Looking to streamline your data integration? AWS Glue is a game-changer. This fully managed ETL service simplifies data preparation, making it easier to analyze and move data across sources. Let’s dive into everything you need to know.





What Is AWS Glue and Why It Matters

AWS Glue is a fully managed extract, transform, and load (ETL) service provided by Amazon Web Services. It enables developers and data engineers to prepare and load data for analytics with minimal manual intervention. Designed for serverless architecture, AWS Glue automatically provisions the resources needed to complete ETL jobs, reducing infrastructure management overhead.
Core Definition and Purpose
AWS Glue is built to automate the time-consuming tasks involved in data integration. Its primary goal is to discover, clean, enrich, and move data between various data stores. Whether you’re migrating data to Amazon S3, Amazon Redshift, or Amazon RDS, AWS Glue streamlines the process with minimal coding.
- Automates schema discovery and data cataloging
- Generates Python or Scala code for ETL workflows
- Supports both batch and streaming data processing
By using AWS Glue, organizations can reduce the time spent on data preparation from weeks to hours, accelerating time-to-insight.
How AWS Glue Fits into the AWS Ecosystem
AWS Glue integrates seamlessly with other AWS services such as Amazon S3, Amazon Athena, Amazon Redshift, and Amazon EMR. It acts as the backbone for data lakes, enabling structured and unstructured data to be cataloged and queried efficiently.
For example, when combined with Amazon Athena, AWS Glue’s Data Catalog allows users to run SQL queries directly on data stored in S3 without needing to define schemas manually. This tight integration reduces complexity and enhances scalability.
“AWS Glue simplifies the ETL process so data engineers can focus on insights, not infrastructure.” — AWS Official Documentation
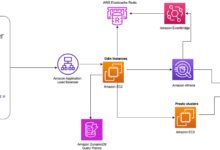
AWS Glue Architecture: Components and Workflow
Understanding the architecture of AWS Glue is essential to leveraging its full potential. The service is composed of several key components that work together to automate data workflows.
Data Catalog and Crawlers
The AWS Glue Data Catalog is a persistent metadata store that acts as a central repository for table definitions, schema information, and partition details. It’s compatible with Apache Hive Metastore, making it easy to integrate with open-source tools.
Crawlers are responsible for scanning data sources—such as S3 buckets, RDS databases, or JDBC connections—and automatically inferring schemas. Once a crawler runs, it populates the Data Catalog with table definitions, including column names, data types, and partition keys.
- Crawlers support multiple data formats: JSON, CSV, Parquet, ORC, and more
- Can be scheduled to run periodically to detect schema changes
- Supports custom classifiers for non-standard formats
For instance, if you store logs in S3 in JSON format, a crawler can detect the structure and create a table in the Data Catalog, making it queryable via Athena or Redshift Spectrum.
ETL Jobs and Scripts
ETL jobs in AWS Glue are the execution units that transform and load data. You can create jobs using the AWS Management Console, CLI, or SDKs. AWS Glue automatically generates Python (PySpark) or Scala (Spark) scripts based on your source and target data.
These scripts run on a serverless Apache Spark environment, meaning you don’t need to manage clusters. AWS Glue dynamically allocates Data Processing Units (DPUs) to handle the workload, scaling up or down based on job complexity.
- Jobs can be triggered manually, on a schedule, or by events (e.g., new file in S3)
- Supports custom transformations using PySpark or Scala
- Allows job bookmarks to track processed data and avoid duplicates
For example, you can set up a job that reads customer data from S3, applies transformations (like filtering invalid records), and loads the cleaned data into Redshift for reporting.
Triggers and Workflows
Triggers define when ETL jobs should run. They can be time-based (cron expressions), event-driven (S3 object creation), or job-based (after another job completes). This flexibility allows for complex orchestration without external tools.
Workflows in AWS Glue enable you to chain crawlers, jobs, and triggers into a single, visual pipeline. This is especially useful for multi-step data pipelines involving data ingestion, transformation, and loading.
- Visual drag-and-drop interface for building workflows
- Supports conditional branching and error handling
- Provides monitoring and logging through CloudWatch
For example, a workflow might start with a crawler detecting new data, followed by a trigger launching a transformation job, and finally loading results into a data warehouse.
Key Features of AWS Glue That Set It Apart
AWS Glue offers several standout features that differentiate it from traditional ETL tools and even other cloud-based solutions. These features make it a powerful choice for modern data engineering teams.
Serverless ETL with Auto-Scaling
One of the most compelling aspects of AWS Glue is its serverless nature. You don’t need to provision or manage servers, clusters, or Spark environments. AWS Glue automatically allocates the necessary compute resources (measured in DPUs) based on job requirements.
Each DPU provides 4 vCPUs and 16 GB of memory, and AWS Glue scales the number of DPUs dynamically. This ensures optimal performance while minimizing cost—especially for sporadic or unpredictable workloads.
- No need to worry about cluster tuning or maintenance
- Pays only for the time jobs are running
- Auto-scales to handle large datasets efficiently
This is particularly beneficial for organizations with fluctuating data volumes, such as e-commerce platforms during peak seasons.
Machine Learning-Powered Data Transformation
AWS Glue includes a feature called Glue Studio and FindMatches, which uses machine learning to identify and deduplicate records. For example, if you have customer data from multiple sources with inconsistent names or addresses, FindMatches can group similar records and suggest merges.
This ML capability reduces the need for complex fuzzy matching logic and accelerates data cleansing. It’s trained on common data patterns and can be customized for specific use cases.
- Reduces manual effort in data deduplication
- Improves data quality and consistency
- Can be integrated into ETL pipelines seamlessly
For instance, a healthcare provider can use FindMatches to consolidate patient records from different clinics, ensuring accurate medical histories.
Integration with Apache Spark and Streaming Data
AWS Glue is built on Apache Spark, giving it robust processing capabilities. It supports both batch and streaming ETL through AWS Glue Streaming, which allows real-time data ingestion from sources like Amazon Kinesis and Amazon MSK (Managed Streaming for Kafka).
Streaming ETL jobs can process data in near real-time, enabling use cases like fraud detection, live dashboards, and IoT data analysis.
- Supports micro-batching for low-latency processing
- Integrates with Kinesis Data Streams and Firehose
- Provides exactly-once processing semantics
For example, a financial institution can stream transaction data, apply risk scoring models, and flag suspicious activities within seconds.
Setting Up Your First AWS Glue Job: Step-by-Step Guide
Creating your first AWS Glue job is straightforward. This guide walks you through setting up a simple ETL pipeline that reads data from S3, transforms it, and writes it back in a different format.
Step 1: Prepare Your Data in S3
Before creating a job, ensure your source data is stored in an S3 bucket. For this example, upload a CSV file named customers.csv with columns like id, name, email, and city.
Create two folders in your bucket: raw/ for input and processed/ for output. This structure helps organize data and permissions.
- Ensure the S3 bucket is in the same region as your Glue job
- Set proper IAM permissions for AWS Glue to access the bucket
- Use prefixes to separate data by date or type
You can use the AWS CLI or console to upload files. Example command: aws s3 cp customers.csv s3://your-bucket/raw/.
Step 2: Create a Crawler to Build the Data Catalog
Go to the AWS Glue Console and navigate to Crawlers. Click Add Crawler and provide a name (e.g., customer-crawler).
Set the data source to your S3 bucket and specify the path (e.g., s3://your-bucket/raw/). Choose an IAM role that grants Glue access to S3. Then, select or create a database in the Data Catalog (e.g., customer_db).
- Run the crawler manually or schedule it
- After completion, check the table in the Data Catalog
- Verify schema detection (e.g., string for name, int for id)
Once the crawler finishes, you’ll see a new table named customers in your database.
Step 3: Create and Run an ETL Job
Now, go to Jobs and click Create Job. Choose the source (the customers table from the Data Catalog) and the target (S3, under processed/).
AWS Glue will auto-generate a PySpark script. You can customize it—e.g., filter out rows where email is null or convert city names to uppercase.
- Select the number of DPUs (start with 2 for small jobs)
- Set job bookmarks to avoid reprocessing
- Add a trigger if you want it to run on a schedule
After saving, run the job. Monitor its progress in the console. Once complete, check the processed/ folder in S3 to see the output (by default, in Parquet format).
“The auto-generated scripts in AWS Glue reduce development time by up to 70%.” — AWS Customer Case Study
Advanced AWS Glue Capabilities for Enterprise Use
For large-scale deployments, AWS Glue offers advanced features that enhance security, performance, and integration with enterprise systems.
Security and Compliance in AWS Glue
Security is a top priority in AWS Glue. It integrates with AWS Identity and Access Management (IAM) to control access to crawlers, jobs, and the Data Catalog. You can define fine-grained permissions using IAM policies.
Data encryption is supported both in transit (TLS) and at rest (using AWS KMS). You can also enable S3 server-side encryption for data stored in buckets accessed by Glue.
- Use IAM roles to grant least-privilege access
- Enable Glue Data Catalog encryption with KMS keys
- Integrate with AWS Lake Formation for centralized data governance
For regulated industries (e.g., finance, healthcare), these features help meet compliance requirements like GDPR, HIPAA, and SOC 2.
Performance Optimization and Cost Management
While AWS Glue is cost-effective, inefficient jobs can lead to high DPU usage. To optimize performance:
- Use job bookmarks to process only new data
- Partition large datasets to reduce scan times
- Choose appropriate file formats (Parquet or ORC over CSV)
- Monitor job metrics in CloudWatch and adjust DPUs
You can also use AWS Glue Elastic Views to create materialized views across multiple data sources without moving data, reducing redundancy and cost.
For example, instead of copying data from RDS and S3 into a data warehouse, Elastic Views can combine them on-the-fly, saving storage and processing costs.
Integration with DevOps and CI/CD Pipelines
Modern data teams use version control and CI/CD for ETL code. AWS Glue supports integration with GitHub, AWS CodeCommit, and CI/CD tools like Jenkins and AWS CodePipeline.
You can store Glue scripts in a repository, test them in staging environments, and deploy them automatically. Using AWS Glue Studio or the CLI, you can parameterize jobs and manage configurations externally.
- Use AWS CloudFormation or Terraform to define Glue resources as code
- Automate testing with AWS Step Functions
- Deploy jobs across environments (dev, test, prod) consistently
This approach improves reliability, auditability, and collaboration across teams.
Common Use Cases for AWS Glue in Real-World Scenarios
AWS Glue is versatile and used across industries for various data integration challenges.
Building and Managing Data Lakes
One of the most common use cases is building data lakes on Amazon S3. AWS Glue crawlers catalog data from diverse sources, and ETL jobs clean and transform it into a structured format (like Parquet) for analytics.
With the Data Catalog, users can query data using Athena, Redshift Spectrum, or EMR, enabling self-service analytics.
- Centralize logs, IoT data, and application data in S3
- Apply schema evolution as data formats change
- Enable governed access via Lake Formation
For example, a retail company can use AWS Glue to ingest sales data from POS systems, online stores, and mobile apps into a unified data lake.
Data Migration and Warehouse Modernization
Organizations migrating from on-premises databases to the cloud use AWS Glue to extract data, transform it to fit modern schemas, and load it into cloud data warehouses like Redshift or Snowflake.
Glue supports JDBC connectors for Oracle, MySQL, PostgreSQL, and SQL Server, making it easy to connect to legacy systems.
- Minimize downtime during migration
- Transform legacy schemas into star or snowflake models
- Validate data consistency post-migration
A financial services firm might use AWS Glue to migrate terabytes of transaction data to Redshift for faster reporting and compliance analysis.
Real-Time Data Processing and Analytics
With AWS Glue Streaming, companies can process data in real time. This is ideal for applications requiring immediate insights, such as monitoring, alerting, and personalization.
For example, a media company can stream user engagement data from a mobile app, enrich it with user profiles, and update recommendation engines in near real time.
- Process clickstream or sensor data with low latency
- Integrate with Amazon QuickSight for live dashboards
- Trigger downstream actions (e.g., send notifications)
This capability transforms batch-oriented systems into responsive, event-driven architectures.
Limitations and Best Practices for AWS Glue
While AWS Glue is powerful, it has limitations. Understanding them helps avoid pitfalls and ensures successful implementations.
Known Limitations and Challenges
Some users report that AWS Glue can be expensive for long-running jobs due to DPU pricing. Additionally, debugging generated scripts can be challenging for complex transformations.
- Startup time for jobs can be slow (1-2 minutes)
- Limited support for non-Spark languages (e.g., no native Python pandas)
- Versioning of scripts is not built-in (requires external tools)
Also, while Glue supports many data sources, some niche databases may require custom connectors or JDBC drivers.
Best Practices for Efficient AWS Glue Usage
To get the most out of AWS Glue:
- Use partitioning and compression to reduce I/O
- Monitor job duration and DPU usage to optimize costs
- Leverage job bookmarks to avoid reprocessing
- Use Glue Development Endpoints for interactive debugging
- Apply schema versioning in the Data Catalog
Additionally, consider using AWS Glue DataBrew for visual data preparation, which complements Glue by allowing non-programmers to clean data before ETL.
Future of AWS Glue: Trends and Roadmap
AWS continues to enhance Glue with new features and integrations. Staying updated on trends ensures your data strategy remains future-proof.
Emerging Trends in Serverless ETL
The shift toward serverless and event-driven architectures is accelerating. AWS Glue is evolving to support more real-time use cases, tighter integration with machine learning services, and improved developer experience.
- Increased support for streaming and change data capture (CDC)
- Better integration with Amazon SageMaker for ML-powered transformations
- Enhanced observability with AWS CloudWatch and X-Ray
Serverless ETL is becoming the standard for agile data teams, reducing time-to-market for new data products.
Expected AWS Glue Enhancements in 2024
Rumors and AWS announcements suggest upcoming improvements:
- Faster job startup times using container pre-warming
- Native support for more data formats and sources
- Improved IDE integration (e.g., VS Code plugin)
- Cost visibility tools for DPU usage forecasting
Additionally, AWS may introduce enhanced support for multi-cloud data integration, allowing Glue to work with data stored in non-AWS environments.
What is AWS Glue used for?
AWS Glue is used for automating ETL (extract, transform, load) processes. It helps discover, clean, transform, and move data between various data stores, making it ideal for building data lakes, migrating databases, and enabling analytics.
Is AWS Glue serverless?
Yes, AWS Glue is a fully serverless service. It automatically provisions and scales the necessary compute resources (DPUs) to run ETL jobs, eliminating the need to manage infrastructure.
How much does AWS Glue cost?
AWS Glue pricing is based on the number of Data Processing Units (DPUs) used per hour. Crawlers, ETL jobs, and development endpoints are billed separately. There’s no upfront cost, and you pay only for what you use. Detailed pricing can be found on the AWS Glue pricing page.
Can AWS Glue handle real-time data?
Yes, AWS Glue supports streaming ETL through AWS Glue Streaming, which can process data from Amazon Kinesis and MSK in near real time, enabling low-latency analytics and event-driven workflows.
How does AWS Glue compare to Apache Airflow?
AWS Glue is focused on ETL automation and serverless execution, while Apache Airflow is a workflow orchestration tool. Glue can generate and run ETL scripts, whereas Airflow schedules and monitors tasks. They can be used together—Airflow can trigger Glue jobs as part of a larger pipeline.
In summary, AWS Glue is a powerful, serverless ETL service that automates data integration tasks, reduces manual coding, and integrates seamlessly with the broader AWS ecosystem. From building data lakes to enabling real-time analytics, it empowers organizations to unlock the value of their data efficiently. By understanding its architecture, features, and best practices, you can design scalable, cost-effective data pipelines that drive business insights. As AWS continues to innovate, Glue is poised to remain a cornerstone of modern data engineering.
Recommended for you 👇
Further Reading:



