Ever wished you could query massive datasets in seconds—without managing servers? AWS Athena makes that dream a reality. This serverless query service lets you analyze data directly from S3 using simple SQL. Fast, flexible, and cost-effective, it’s reshaping how businesses handle big data.





What Is AWS Athena and How Does It Work?

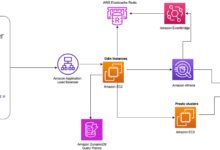
AWS Athena is a serverless query service that allows users to analyze data stored in Amazon S3 using standard SQL. Unlike traditional data warehousing solutions, Athena requires no infrastructure setup, cluster management, or server provisioning. It’s designed for simplicity, scalability, and speed—making it ideal for organizations looking to extract insights from large datasets without the overhead of managing databases.
Serverless Architecture Explained
The term “serverless” can be misleading. It doesn’t mean there are no servers—it means you don’t have to manage them. AWS handles all the backend infrastructure, including compute resources, scaling, and maintenance. When you run a query in AWS Athena, the service automatically provisions the necessary compute power, executes your SQL query, and shuts down the resources when done.
- No need to launch EC2 instances or configure clusters.
- Scaling is automatic and instantaneous based on query complexity and data volume.
- You only pay for the queries you run, measured in gigabytes scanned.
“Athena abstracts away the infrastructure so developers and analysts can focus on data, not servers.” — AWS Official Documentation
Integration with Amazon S3
AWS Athena is deeply integrated with Amazon S3, the cloud storage service used by millions of organizations worldwide. Data doesn’t need to be moved or transformed before querying. You simply point Athena to your S3 bucket, define a schema, and start running SQL queries.
- Data remains in S3—no data migration required.
- Supports various file formats: CSV, JSON, Parquet, ORC, Avro, and more.
- Works seamlessly with partitioned and compressed data.
This tight integration reduces latency and eliminates ETL bottlenecks, enabling real-time analytics on raw data lakes. For example, a retail company can store years of sales logs in S3 and use AWS Athena to instantly analyze customer behavior trends without building a data warehouse.
Key Features That Make AWS Athena Stand Out
AWS Athena isn’t just another query engine—it’s packed with features that make it a go-to solution for modern data analysis. From its seamless integration with other AWS services to advanced performance optimizations, Athena delivers both power and simplicity.
Federated Query Capability
One of the most powerful features introduced in AWS Athena is federated querying. This allows you to run SQL queries across multiple data sources—both within AWS and external systems—without moving data.
- Query relational databases like Amazon RDS, Aurora, and Redshift.
- Access data in on-premises systems via AWS Glue Data Catalog.
- Combine S3 data with operational databases in a single SELECT statement.
This capability transforms Athena into a unified analytics layer. For instance, a financial analyst can join transaction data from an RDS PostgreSQL database with historical logs in S3 to generate comprehensive reports—all within one query.
Support for Open Table Formats (Iceberg, Delta, Hudi)
In recent years, AWS Athena has evolved beyond basic S3 querying. It now supports open table formats like Apache Iceberg, Delta Lake, and Apache Hudi. These formats bring database-like capabilities—such as ACID transactions, time travel, and schema evolution—to data lakes.
- Apache Iceberg enables efficient querying of large tables with complex partitioning.
- Delta Lake provides versioning and rollback capabilities.
- Hudi supports incremental data processing and upserts.
By supporting these open standards, AWS Athena empowers organizations to build modern, scalable data architectures without vendor lock-in. You can read more about this feature in the official AWS blog post on Iceberg support.
How to Get Started with AWS Athena: Step-by-Step Setup
Getting started with AWS Athena is straightforward, even for beginners. Whether you’re a data analyst, developer, or DevOps engineer, you can be up and running in under 15 minutes.
Step 1: Prepare Your Data in S3
Before using AWS Athena, ensure your data is stored in an S3 bucket. Organize your files logically—ideally partitioned by date, region, or category to improve query performance and reduce costs.
- Use consistent naming conventions (e.g.,
sales-data-2024-04-01.csv). - Compress files using GZIP or Snappy to reduce storage and scanning costs.
- Convert data to columnar formats like Parquet or ORC for faster queries.
For example, if you’re analyzing web logs, store them in a structure like s3://my-log-bucket/year=2024/month=04/day=05/. This enables partition pruning in AWS Athena, which skips irrelevant data during queries.
Step 2: Create a Database and Table in Athena
Once your data is in S3, log into the AWS Management Console, navigate to Athena, and create a database.
- Run
CREATE DATABASE my_analytics_db; - Then define a table using CTAS (Create Table As Select) or manual DDL.
- Specify the data format, location, and schema (columns and types).
Example:
CREATE EXTERNAL TABLE IF NOT EXISTS logs_table (
timestamp STRING,
user_id STRING,
action STRING,
page STRING
)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY ','
STORED AS TEXTFILE
LOCATION 's3://my-log-bucket/';
You can also use the AWS Glue Crawler to automatically detect schema and populate the Data Catalog, saving time on manual table creation.
Step 3: Run Your First Query
With the table created, you’re ready to query. Type a simple SQL statement in the Athena query editor:
SELECT action, COUNT(*) AS count
FROM logs_table
GROUP BY action
LIMIT 10;
Click “Run Query.” Athena will scan the data in S3, execute the operation, and return results in seconds. The cost is based on the amount of data scanned—so optimizing file format and partitioning helps reduce expenses.
Performance Optimization Techniques in AWS Athena
While AWS Athena is fast by design, performance can vary depending on how your data is structured and queried. Implementing best practices can significantly reduce query latency and cost.
Use Columnar File Formats (Parquet, ORC)
One of the most effective ways to boost AWS Athena performance is to store data in columnar formats like Apache Parquet or ORC. Unlike row-based formats (e.g., CSV), columnar formats store data by columns, allowing Athena to read only the fields needed for a query.
- Queries scan less data, reducing costs.
- Better compression ratios lower storage and I/O overhead.
- Improved performance for aggregation and filtering operations.
For example, if your table has 20 columns but your query only uses 3, Parquet will skip the other 17 entirely. This can reduce scan volume by 80% or more.
Partition Your Data Strategically
Partitioning divides your dataset into logical chunks based on values like date, region, or category. AWS Athena uses partition pruning to exclude irrelevant partitions during query execution.
- Common partition keys:
year,month,day,country. - Avoid over-partitioning (e.g., per hour or minute), which can create too many small files.
- Use AWS Glue Partition Index for large tables to speed up metadata operations.
Example S3 structure:
s3://my-data-bucket/sales/year=2024/month=04/day=05/data.parquetQuery:
SELECT * FROM sales_table WHERE year = '2024' AND month = '04';Athena will only scan data from April 2024, ignoring all other months.
Leverage AWS Athena Workgroups and Query Results Caching
Workgroups in AWS Athena allow you to manage query execution, set data usage limits, and enforce cost controls. They also enable result caching—so identical queries return instantly without reprocessing.
- Enable caching in workgroup settings.
- Set byte limits to prevent runaway queries.
- Assign different workgroups to teams (e.g., analytics, engineering).
Caching is especially useful for dashboards or recurring reports that run the same queries daily. The first execution might take 10 seconds; subsequent runs take less than a second.
Security and Access Control in AWS Athena
Security is critical when dealing with sensitive data. AWS Athena integrates with AWS Identity and Access Management (IAM), AWS Lake Formation, and encryption protocols to ensure secure data access.
IAM Policies for Fine-Grained Access
You can control who can run queries, which databases they can access, and what actions they can perform using IAM policies. For example:
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Action": [
"athena:StartQueryExecution",
"athena:GetQueryResults"
],
"Resource": "arn:aws:athena:us-east-1:123456789012:workgroup/analysts"
}
]
}
- Restrict access to specific workgroups.
- Limit query execution to certain S3 buckets.
- Enforce tagging for cost allocation.
This ensures that only authorized users can interact with AWS Athena, reducing the risk of accidental or malicious queries.
Data Encryption and Compliance
AWS Athena supports both server-side and client-side encryption for data at rest and in transit.
- Query results are stored in S3 and can be encrypted using SSE-S3, SSE-KMS, or CSE-C.
- S3 buckets should have default encryption enabled.
- Use AWS Lake Formation to centrally manage permissions across S3, Glue, and Athena.
For regulated industries (e.g., healthcare, finance), these features help meet compliance standards like HIPAA, GDPR, and SOC 2. You can learn more about securing Athena in the AWS Athena Security Guide.
Cost Management and Pricing Model of AWS Athena
Understanding AWS Athena’s pricing is essential for budgeting and optimization. The service follows a pay-per-query model, making it highly cost-efficient for sporadic or exploratory analytics.
Pricing Structure: $5 per TB Scanned
AWS Athena charges $5.00 per terabyte (TB) of data scanned. You are not billed for failed queries or queries that return no results. This model incentivizes efficient data layout and query design.
- A 1 GB query costs $0.005.
- Scanning 10 TB per month = $50.
- No charges for storage, compute, or idle time.
Compare this to traditional data warehouses like Amazon Redshift, which charge for node hours regardless of usage. Athena is often cheaper for low-to-medium query volumes.
Strategies to Reduce Athena Costs
While Athena is affordable, costs can add up with inefficient queries. Here are proven strategies to minimize spending:
- Convert to Parquet/ORC: Reduces scan size by up to 90%.
- Partition data: Avoid full table scans.
- Use CTAS to pre-aggregate: Create summary tables for frequent reports.
- Limit SELECT * queries: Only fetch required columns.
- Enable result reuse: Cache repeated queries.
For example, a company reduced its monthly Athena bill from $800 to $120 by converting CSV logs to partitioned Parquet files and implementing query caching.
Real-World Use Cases of AWS Athena
AWS Athena is used across industries for a wide range of applications. Its flexibility and ease of use make it ideal for both technical and non-technical users.
Log Analysis and Security Monitoring
Organizations use AWS Athena to analyze VPC flow logs, CloudTrail logs, and application logs stored in S3. Security teams can detect anomalies, audit access patterns, and investigate incidents using SQL.
- Query CloudTrail to find unauthorized API calls.
- Analyze VPC logs for unusual traffic patterns.
- Monitor user login attempts across AWS accounts.
Example query:
SELECT sourceIPAddress, eventName, COUNT(*)
FROM cloudtrail_logs
WHERE eventTime BETWEEN '2024-04-01T00:00:00Z' AND '2024-04-02T00:00:00Z'
AND errorCode IS NOT NULL
GROUP BY sourceIPAddress, eventName;Business Intelligence and Reporting
With integration into tools like Amazon QuickSight, Tableau, and Looker, AWS Athena serves as a backend for interactive dashboards and executive reports.
- Connect BI tools directly to Athena via JDBC/ODBC.
- Run ad-hoc queries to explore sales, marketing, or customer data.
- Generate daily KPI reports with scheduled queries.
A retail chain uses AWS Athena to power its sales dashboard, combining inventory data, POS transactions, and customer demographics—all queried in real time from S3.
Data Lake Querying for Machine Learning
Data scientists use AWS Athena to explore and preprocess training data before feeding it into SageMaker or other ML platforms.
- Filter and sample large datasets.
- Validate data quality and schema consistency.
- Generate feature summaries for model development.
For example, a fintech startup uses Athena to extract transaction patterns from 5 years of banking data, then exports the results to Parquet for model training.
Common Challenges and How to Overcome Them
Despite its advantages, AWS Athena comes with some limitations. Being aware of these challenges helps you design better architectures and avoid pitfalls.
Latency for Complex Queries
While simple queries return in seconds, complex joins or large scans can take minutes. This makes Athena less suitable for real-time applications.
- Solution: Pre-process data using AWS Glue or EMR to create summarized tables.
- Use materialized views (via CTAS) for frequently accessed datasets.
- Consider Redshift for sub-second response requirements.
No Native Indexing Support
Unlike traditional databases, AWS Athena doesn’t support indexes. Performance relies entirely on file format, partitioning, and compression.
- Solution: Use Z-Ordering in Parquet files to co-locate related data.
- Leverage bucketing for high-cardinality columns.
- Apply predicate pushdown to filter early.
Query Concurrency Limits
By default, AWS Athena allows up to 20 concurrent queries per workgroup. High-volume environments may hit this limit.
- Solution: Request a quota increase from AWS Support.
- Use asynchronous query execution with SDKs.
- Implement queuing logic in applications.
Future of AWS Athena: Trends and Roadmap
AWS continues to invest heavily in Athena, adding features that align with modern data architecture trends like data mesh, open formats, and hybrid analytics.
Growing Support for Open Data Standards
AWS is pushing Athena toward open ecosystems. With support for Iceberg, Delta Lake, and Hudi, Athena is becoming a universal query engine for multi-format data lakes.
- Reduces dependency on proprietary systems.
- Enables cross-platform data sharing.
- Supports time travel and schema evolution.
Enhanced Performance with Athena Engine Version 3
Athena now offers multiple engine versions. Version 3 provides up to 3x faster performance for common queries by optimizing query planning and execution.
- Better handling of nested data (JSON, arrays).
- Improved cost efficiency through smarter scanning.
- Backward compatible with previous versions.
You can read more about performance improvements in the Athena Engine V3 announcement.
Integration with AWS Lake Formation and IAM Identity Center
Future updates are expected to deepen integration with AWS Lake Formation for centralized governance and IAM Identity Center for single sign-on across analytics tools.
- Unified permissions across S3, Glue, and Athena.
- Role-based access for external users.
- Audit trails for compliance reporting.
These enhancements will make AWS Athena even more enterprise-ready.
Comparison: AWS Athena vs. Alternatives
While AWS Athena is powerful, it’s not the only option. Let’s compare it with similar services to understand when to choose what.
AWS Athena vs. Amazon Redshift
Redshift is a fully managed data warehouse for high-performance analytics. It’s ideal for complex queries and large-scale reporting.
- Athena: Serverless, pay-per-query, great for ad-hoc analysis.
- Redshift: Cluster-based, hourly pricing, better for continuous workloads.
- Use Athena for exploration; Redshift for production BI.
AWS Athena vs. Google BigQuery
BigQuery is Google Cloud’s serverless data warehouse. Both offer similar SQL interfaces and pricing models.
- Athena: Tightly integrated with S3 and AWS ecosystem.
- BigQuery: Native streaming, ML integration, global multi-region support.
- Choose based on cloud provider preference and existing infrastructure.
AWS Athena vs. Snowflake
Snowflake is a cloud-native data platform known for performance and ease of use.
- Athena: Lower cost for infrequent queries, simpler setup.
- Snowflake: Superior concurrency, advanced optimization, broader SQL support.
- Snowflake excels in enterprise data warehousing; Athena in lightweight analytics.
Ultimately, AWS Athena shines when you need fast, simple, and cost-effective querying of S3 data without operational overhead.
What is AWS Athena used for?
AWS Athena is used to run SQL queries on data stored in Amazon S3 without needing to manage servers or data warehouses. It’s commonly used for log analysis, business intelligence, data lake querying, and ad-hoc analytics.
Is AWS Athena free to use?
AWS Athena is not free, but it has a pay-per-query pricing model. You pay $5 per terabyte of data scanned. There is no charge for storage or failed queries, and the first 1 MB of data scanned per query is free.
How fast is AWS Athena?
Query speed in AWS Athena depends on data size, format, and complexity. Simple queries on optimized data (e.g., Parquet) return in seconds. Large or complex queries may take minutes. Engine Version 3 offers up to 3x faster performance for common operations.
Can AWS Athena query JSON or nested data?
Yes, AWS Athena supports JSON and nested data types. You can use built-in functions like JSON_EXTRACT or CAST to parse and query semi-structured data. Performance improves when using columnar formats like Parquet with proper schema definition.
Does AWS Athena support joins and subqueries?
Yes, AWS Athena supports SQL joins (INNER, LEFT, RIGHT), subqueries, window functions, and complex aggregations. However, performance depends on data layout and size, so optimizing file formats and partitioning is crucial for efficient joins.
In conclusion, AWS Athena is a game-changer for organizations looking to unlock insights from their data lakes without the complexity of traditional databases. Its serverless nature, seamless S3 integration, and support for modern data formats make it a powerful tool for developers, analysts, and data engineers alike. Whether you’re analyzing logs, generating reports, or preparing data for machine learning, AWS Athena offers a fast, flexible, and cost-effective solution. As AWS continues to enhance its capabilities—especially in open table formats and performance—it’s poised to remain a cornerstone of cloud analytics for years to come.
Recommended for you 👇
Further Reading:



